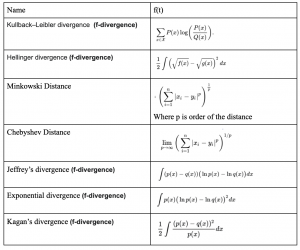
To compare a model’s fit to empirical data (and to compare across models) traditionally the Pearson goodness-of-fit test statistic or the traditional log likelihood ratio test statistic are used, and the unknown parameters are estimated using the maximum likelihood method. However, it is well known that this can give a poor approximation in many circumstances and it is possible to get better results by considering general families of test statistics. There are many divergence metics that have been developed, here is a summary:
Many metrics belong to a class called f-divergence, which have useful properties (can be expressed as taylor series, guarantee non-negativity, etc.). P and Q, f and g, x and y, A and B, I and M, are all used interchangeably to symbolize two distributions whose divergence is to be computed.